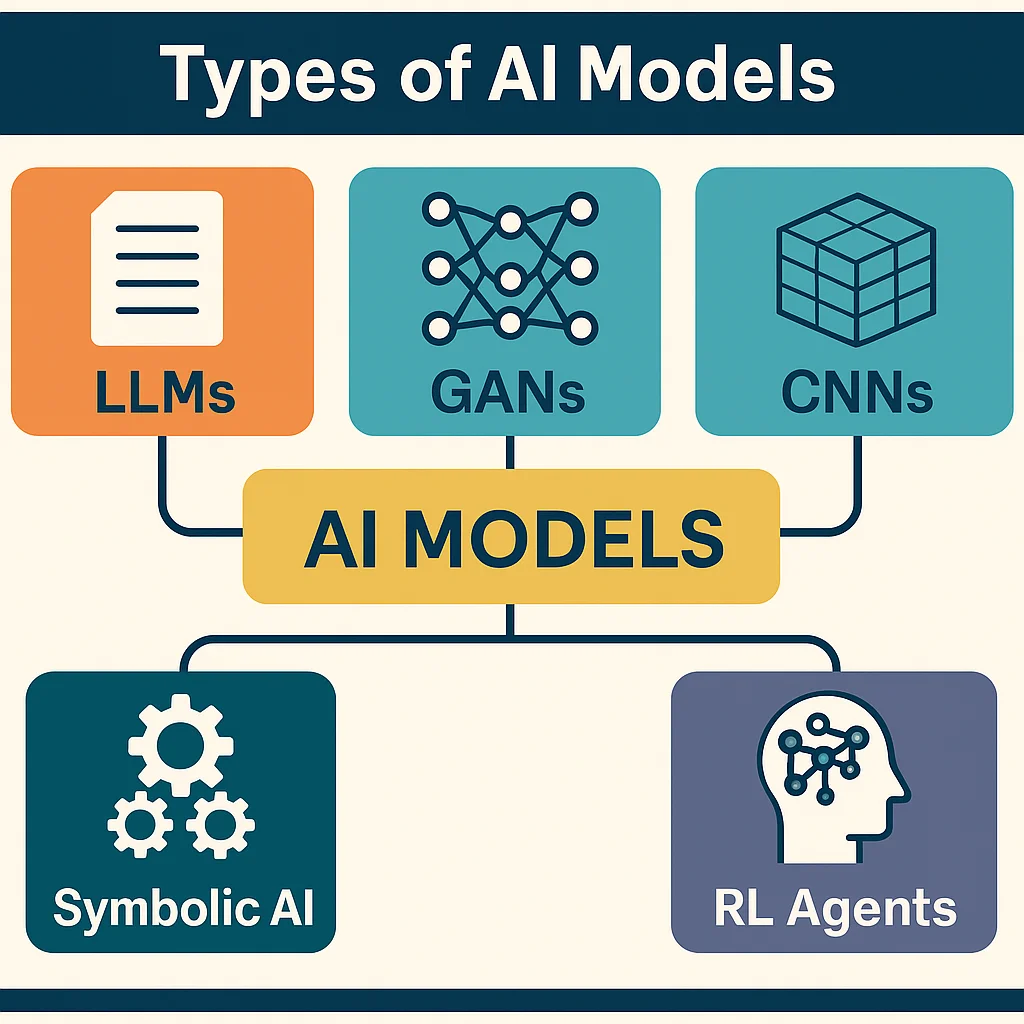
Types of AI Models: From LLMs to Reinforcement Learners
Introduction
When people say "AI," they might be referring to anything from a chatbot to a self-driving car — but not all AI is built the same. Under the hood, different AI systems are powered by different types of models, each with its own architecture, strengths, and limitations. Some are built to generate content. Others classify, recommend, or explore environments to maximize rewards. Understanding these differences is crucial to navigating the ever-expanding world of artificial intelligence.
This article explores the major types of AI models used today, from Large Language Models (LLMs) like ChatGPT and Claude, to older symbolic systems, image-generation frameworks, and reinforcement learners like AlphaGo. By the end, you’ll have a clear map of what powers the tools reshaping everything from search engines to art studios.
Large Language Models (LLMs)
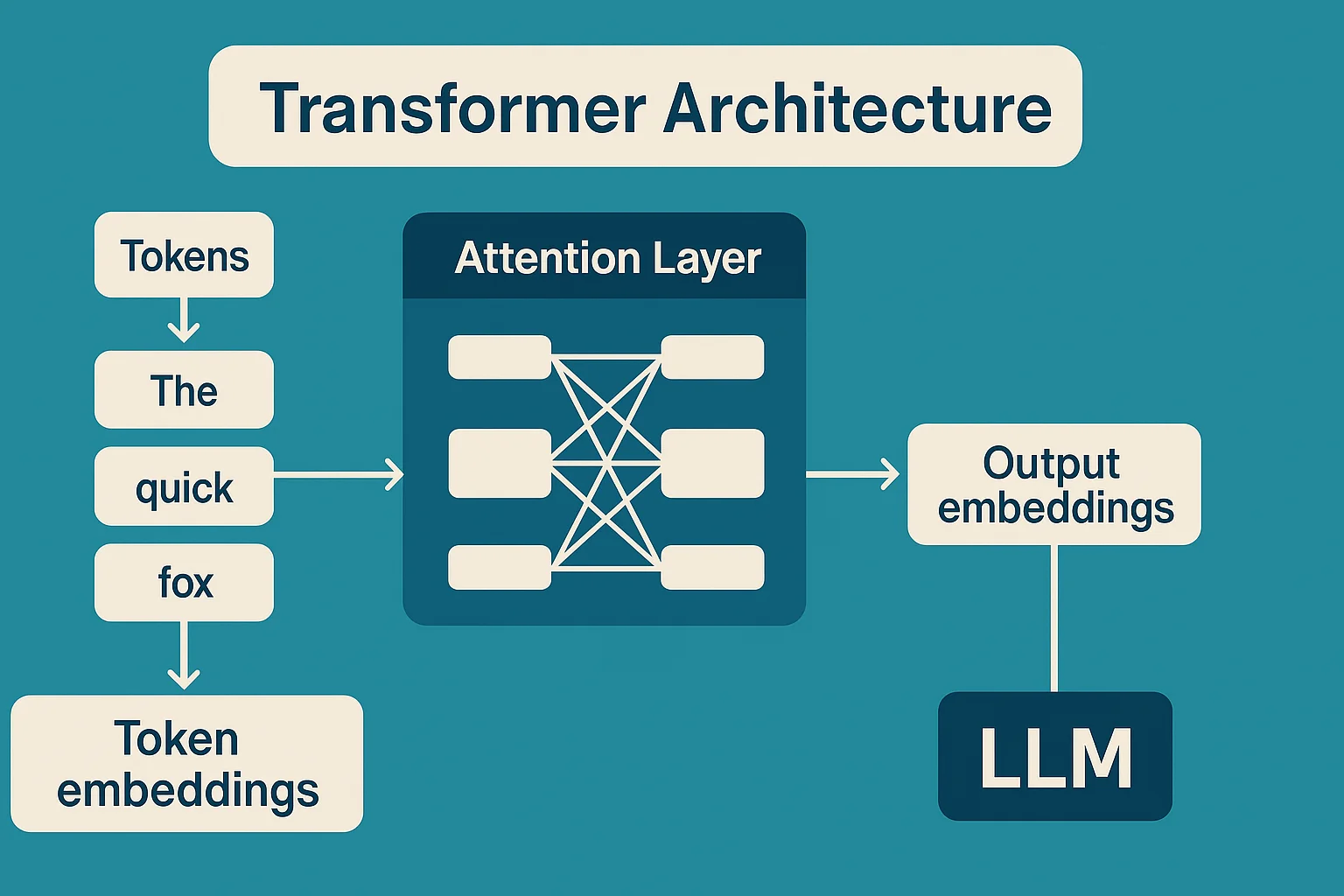
Large Language Models have become the face of modern AI — powering tools like ChatGPT, Gemini, Claude, and Copilot. These models are built on a deep learning architecture called the transformer, which excels at handling sequences of text.
LLMs are trained on massive corpora of text — books, websites, codebases, articles — and learn to predict the next token (a word or subword) in a sequence. Over time, this simple mechanism allows them to learn grammar, facts, reasoning patterns, and even subtle stylistic cues.
Key characteristics of LLMs:
- Architecture: Transformer-based, often with billions of parameters
- Training objective: Next-token prediction
- Strengths: Text generation, summarization, translation, question answering, reasoning
- Limitations: Hallucination, lack of grounding, large resource requirements
What makes LLMs unique is their generality. Once pretrained, they can be fine-tuned or instructed to perform dozens of tasks without needing separate models. This flexibility is why LLMs are often referred to as “foundation models.”
Generative Models
Generative models are designed to create new content — whether it’s text, images, video, audio, or code. LLMs are one kind of generative model, but several other types exist, each suited to different kinds of outputs.
Three common types of generative models:
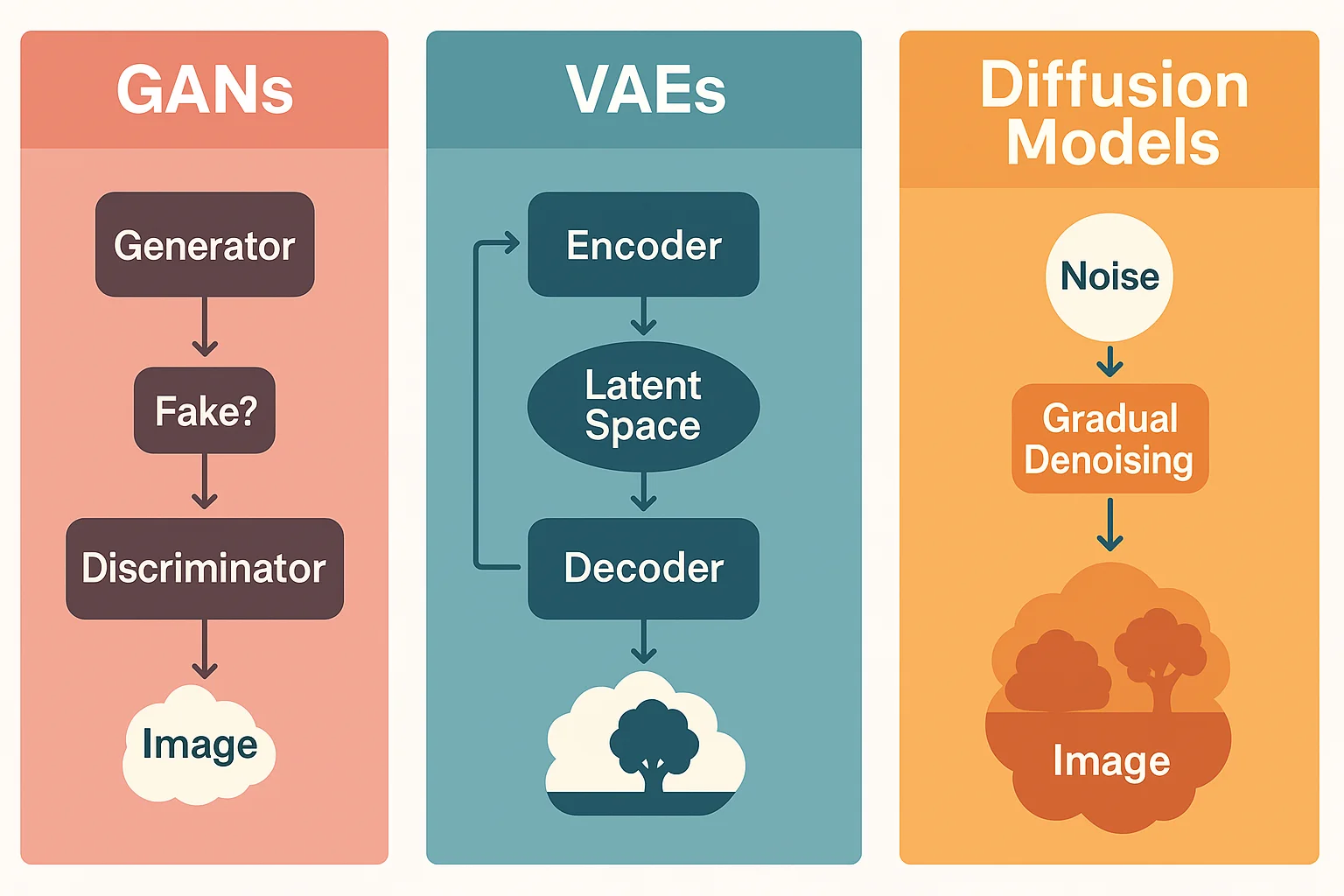
- GANs (Generative Adversarial Networks): These pit two neural networks against each other — a generator that creates data, and a discriminator that tries to spot fakes. This adversarial training produces realistic outputs, especially in image synthesis (e.g., ThisPersonDoesNotExist.com).
- VAEs (Variational Autoencoders): These compress data into a latent space and then reconstruct it. They’re good for structured generation but tend to produce blurrier images than GANs.
- Diffusion Models: These models, like those behind DALL·E 2, Stable Diffusion, and Midjourney, gradually transform random noise into coherent images. They have largely overtaken GANs in artistic quality and diversity.
- Art and design
- Code generation
- Music composition
- Text-to-image conversion
- Deepfake creation (both benign and malicious)
Generative models are widely used in:
They represent a powerful — and controversial — arm of AI, raising questions about authorship, originality, and ethical use.
Discriminative Models
While generative models produce data, discriminative models focus on classification and prediction. They learn to distinguish between categories or predict values based on input features.
Examples include:
- Logistic Regression: A basic linear-model used for binary-classification.
- Support Vector Machines (SVMs): Classify data by finding the optimal separating hyperplane.
- Random Forests: Ensemble models based on decision trees.
- Gradient Boosting Machines (GBMs): Powerful for tabular-data and often used in competitions like Kaggle.
Even within neural networks, discriminative tasks remain crucial. For instance:
- BERT (Bidirectional Encoder Representations from Transformers) is used for classification, not generation.
- ResNet is a deep CNN architecture used for image classification.
Discriminative models are core to applications like:
- Spam detection
- Fraud detection
- Medical diagnostics
- Sentiment analysis
- Search ranking
They are often more efficient than generative models for specific, narrow tasks — especially when interpretability and speed matter.
Symbolic AI (GOFAI)
Before the rise of neural networks, AI was dominated by symbolic systems — also known as GOFAI (“Good Old-Fashioned AI”). These systems used explicitly defined rules, logic, and symbolic representations to make decisions and perform reasoning.
Key features of symbolic AI:
- Rule-based inference: Uses IF-THEN logic
- No learning: Behavior is fully hand-coded
- Explainable: Every decision traceable to specific rules
- Brittle: Performs poorly outside its intended domain
Examples include:
- Expert systems like MYCIN (medical diagnosis)
- Logic programming in languages like Prolog
- Game AIs using rule trees or decision tables
While symbolic AI fell out of favor in the deep learning era, it’s making a quiet comeback. Hybrid systems now seek to combine symbolic reasoning with neural networks — blending interpretability with adaptability. Some researchers believe this hybrid approach is key to achieving more trustworthy and explainable AI in high-stakes fields like law or medicine.
Reinforcement Learning (RL)
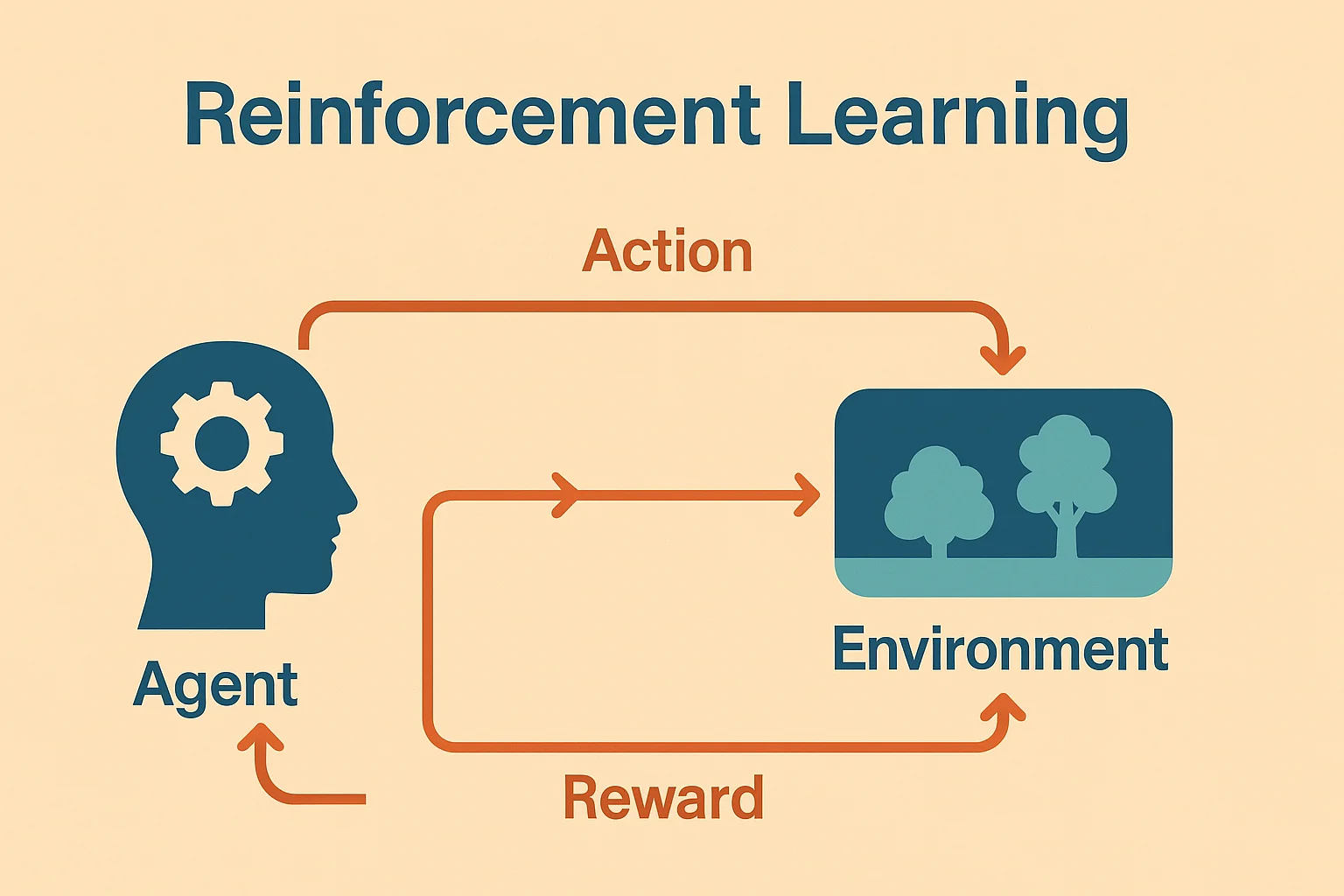
Reinforcement Learning is a unique branch of AI focused on agents that learn by interacting with an environment. Rather than being trained on a fixed dataset, RL systems improve by trial and error — receiving rewards for desirable outcomes and penalties for undesirable ones.
At the core of RL is the agent-environment loop:
- The agent observes the current state
- It takes an action
- The environment returns a reward and a new state
- The agent updates its strategy (policy) to maximize cumulative reward
Some well-known RL applications include:
- AlphaGo and AlphaZero by DeepMind, which defeated human champions in complex board games
- Robotics, where agents learn how to walk, grasp, or fly
- Resource management, like controlling traffic flow or energy grids
- Game AI, from real-time strategy games to complex simulations
Key algorithms:
- Q-learning: Table-based or neural-approximation method to estimate value of actions
- Policy Gradient: Directly optimize the action selection policy
- Actor-Critical models: Combine both value-based and policy-based learning
RL is powerful, but it comes with steep challenges: sample inefficiency, instability, and difficulty in defining safe reward functions. Nonetheless, it remains the go-to method when AI must learn to take actions in dynamic, uncertain environments.
Multimodal Models
Humans naturally integrate multiple forms of input — sight, sound, language, motion — to understand the world. Multimodal models aim to bring this ability to AI by fusing data from different modalities (e.g., text, images, video, audio, code) into a single system.
Recent advances in this area include:
Multimodal systems enable richer AI capabilities and are likely to power the next generation of interfaces — from AR glasses to AI assistants that interact with the real world.
Transformer Models
The transformer architecture, introduced in the 2017 paper “Attention Is All You Need”, revolutionized machine learning. It replaced older sequence models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory) by enabling:
- Parallelization: Processes all tokens at once, allowing faster training
- Attention mechanisms: Each word or token can attend to every other token — providing better context
Transformers are the backbone of most modern AI models, powering LLMs, vision transformers, speech models, and more. Their scalability and versatility have made them dominant — but also resource-intensive and opaque.
Other Architectures: CNNs, RNNs, and Beyond
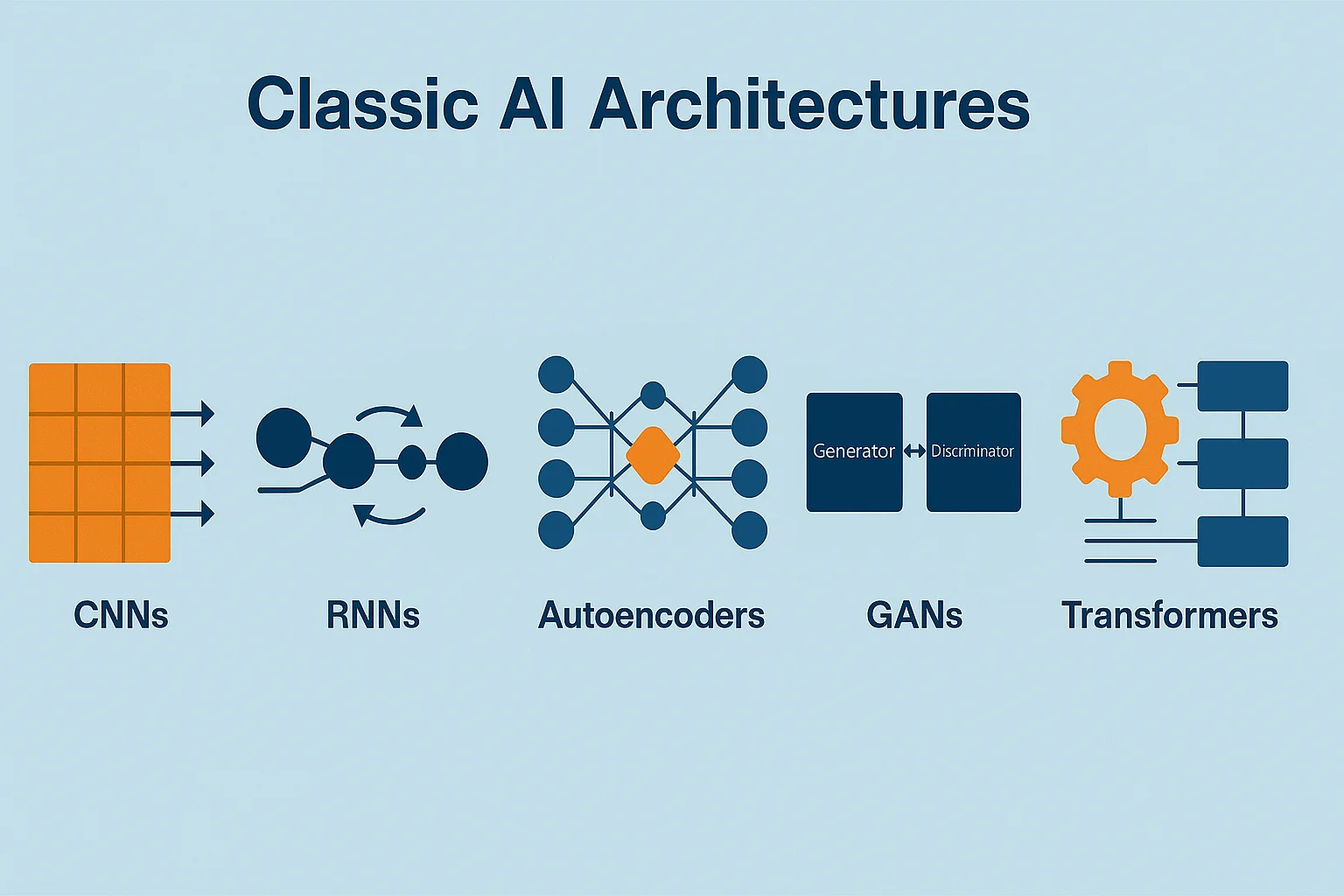
Before transformers became dominant, many specialized architectures were used for domain-specific problems — and they’re still relevant today.
CNNs (Convolutional Neural Networks): Primarily used in image processing and computer vision. They use filters to detect edges, textures, and complex features in images.
RNNs (Recurrent Neural Networks): Used for sequential data (e.g., text, time series, audio), RNNs maintain a hidden state to capture temporal dependencies. However, they struggle with long-term dependencies and suffer from vanishing gradients.
Variants like:
- LSTMs (Long Short-Term Memory)
- GRUs (Gated Recurrent Units)
Other Notable Architectures:
- Autoencoders: Used for dimensionality redution and anomaly detection
- Capsule Networks: Try to preserve spatial relationships in images
- Graph Neural Networks (GNNs): Model relationships between entities in graph structures
Even as transformers dominate, these older architectures remain useful — especially in mobile applications, edge devices, and structured data scenarios where performance and efficiency are key.
Conclusion
The AI models powering today’s tools are as diverse as the tasks they perform. From content generators to pattern classifiers, from symbolic logic engines to deep reinforcement learners — each type of model represents a different approach to replicating aspects of intelligence.
We’ve seen how LLMs generate fluid language, how GANs and diffusion models create art and images, how reinforcement learning powers agents that explore, and how transformers sit at the heart of modern AI breakthroughs. We’ve also revisited older models like CNNs and symbolic systems, which continue to find niche applications.
As the field evolves, we’re seeing a push toward more general-purpose, hybrid models — blending different capabilities into unified architectures. Understanding the differences between these model types gives us better insight into what AI can (and can’t) do — and where it might be headed next.
Whether you’re building tools, regulating systems, or just using AI in daily life, knowing what’s under the hood makes you a more informed participant in the future of technology.