Understanding Machine Learning Algorithms
Introduction
Machine learning may seem mysterious — like a kind of digital wizardry powering everything from chatbots and search engines to facial recognition and self-driving cars. But at its core, machine learning is built on a set of algorithms: mathematical recipes that tell a computer how to learn patterns from data.
These algorithms are not just for coders or data scientists. Understanding the basic principles behind them helps anyone — students, professionals, decision-makers — think more critically about how AI works, what it can do, and where it might go wrong.
In this article, we’ll walk through the major types of machine learning algorithms in a beginner-friendly way, using simple examples to show how machines actually “learn.” You don’t need a math degree — just curiosity.
What Is a Machine Learning Algorithm?
At its simplest, a machine learning algorithm is a set of instructions that tells a computer how to make predictions or decisions based on data. Unlike traditional software, where programmers write exact rules, ML algorithms figure out the rules by analyzing patterns in examples.
Think of it like this: Instead of telling a computer “a cat has pointy ears, whiskers, and a tail,” you give it thousands of labeled pictures of cats and non-cats, and it figures out the pattern on its own. The more data it sees, the better it gets at making accurate predictions — assuming the right algorithm is used.
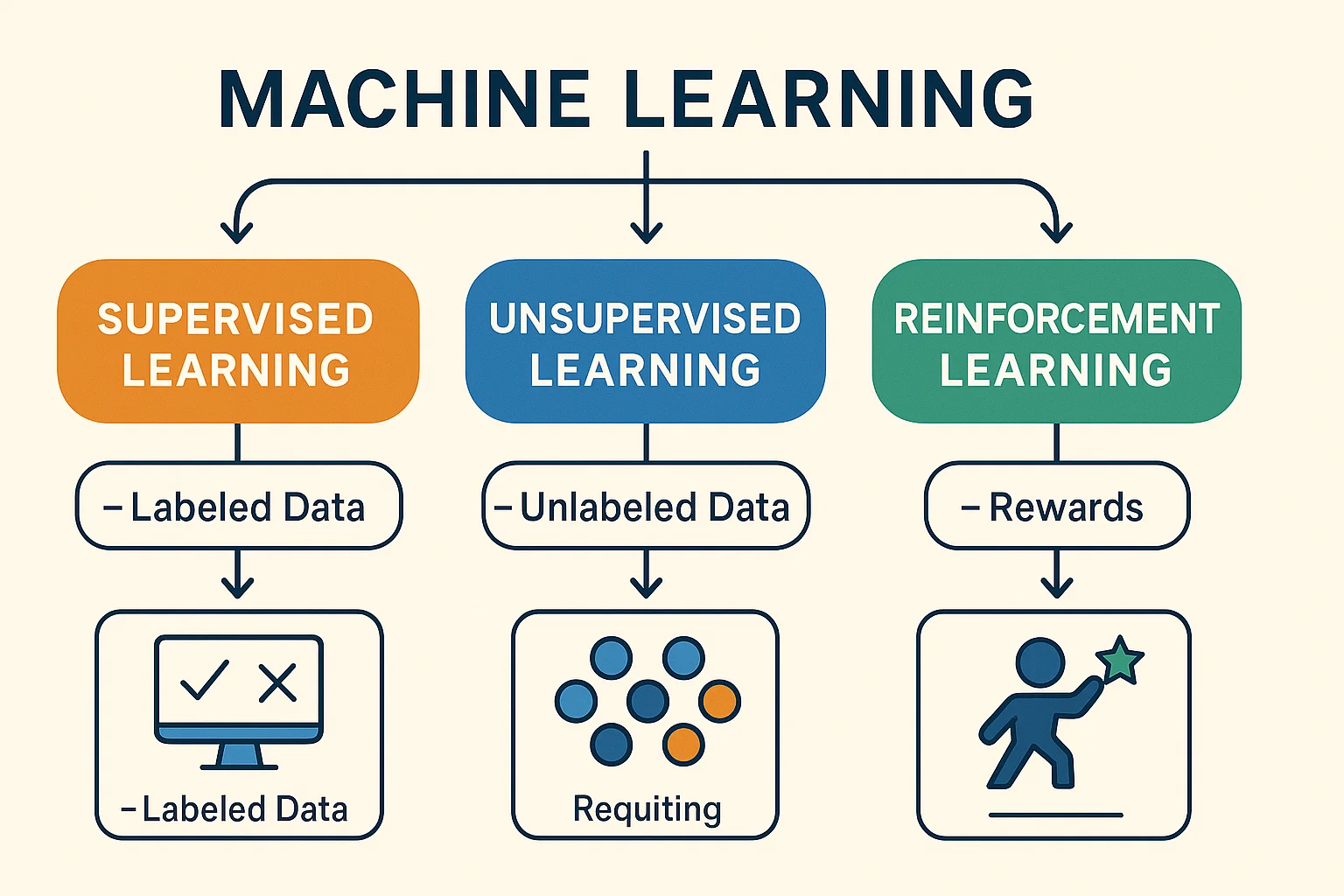
There are many types of algorithms, and they’re usually grouped by how they learn from data. The three main categories are:
- Aupervised learning – Learning from labeled data
- Unsupervised learning – Finding patterns in unlabeled data
- Reinforcement learning – Learning through rewards and trial/error
Let’s start with the most common: supervised learning.
Supervised Learning Algorithms
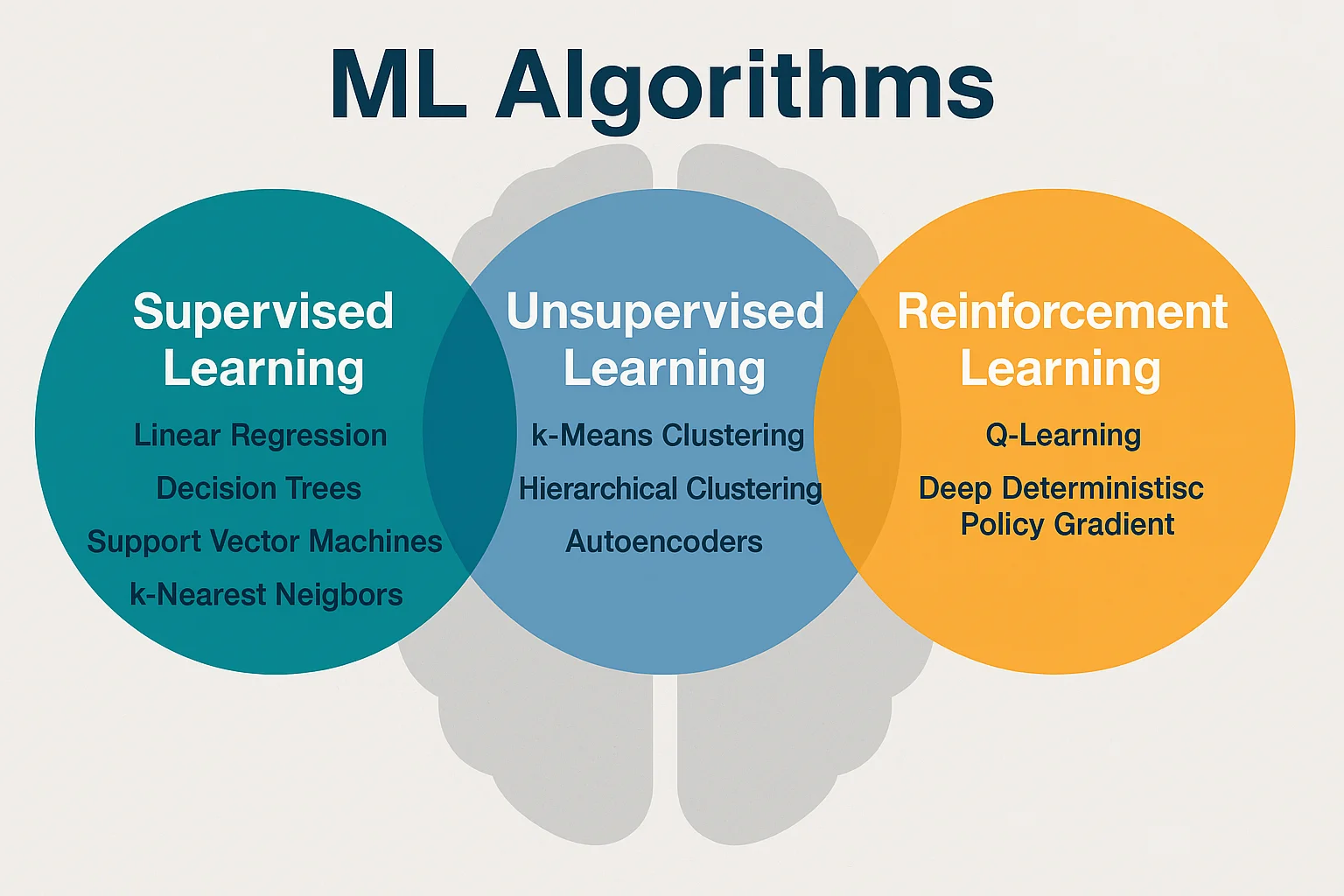
In supervised learning, the algorithm is trained on labeled examples. Each training example consists of an input (e.g., an image or a list of numbers) and a correct output (e.g., “dog” or “not spam”). The algorithm tries to learn a function that maps inputs to outputs.
Here are a few popular supervised learning algorithms:
🔹 Linear Regression
This is one of the simplest algorithms and is used for predicting numeric values. For example, you might use it to predict someone’s weight based on their height. Linear regression tries to draw a straight line through the data that best fits the trend.
It’s widely used in business forecasting, pricing models, and basic trend analysis.
🔹 Logistic Regression
Despite the name, this is used for classification, not regression. It’s great for binary problems — like whether an email is spam or not. It outputs a probability between 0 and 1, and a threshold is used to make a decision.
Simple, fast, and surprisingly effective for many real-world tasks.
🔹 Decision Trees
Decision trees mimic human decision-making by asking a sequence of “if/then” questions. For example:
“If income > $50,000 → go left, else → go right.”
They split the data into branches and leaf nodes, leading to a final decision.
Pros: Easy to understand and interpret.
Cons: Can overfit to training data unless carefully pruned.
🔹 Support Vector Machines (SVM)
SVMs are powerful classifiers that work by finding the best boundary (or “hyperplane”) that separates classes in your data. If the data isn’t linearly separable, they can use something called a kernel trick to project the data into a higher-dimensional space where it is.
SVMs are great for problems with clear boundaries and work well in fields like image recognition or document classification.
Unsupervised Learning Algorithms
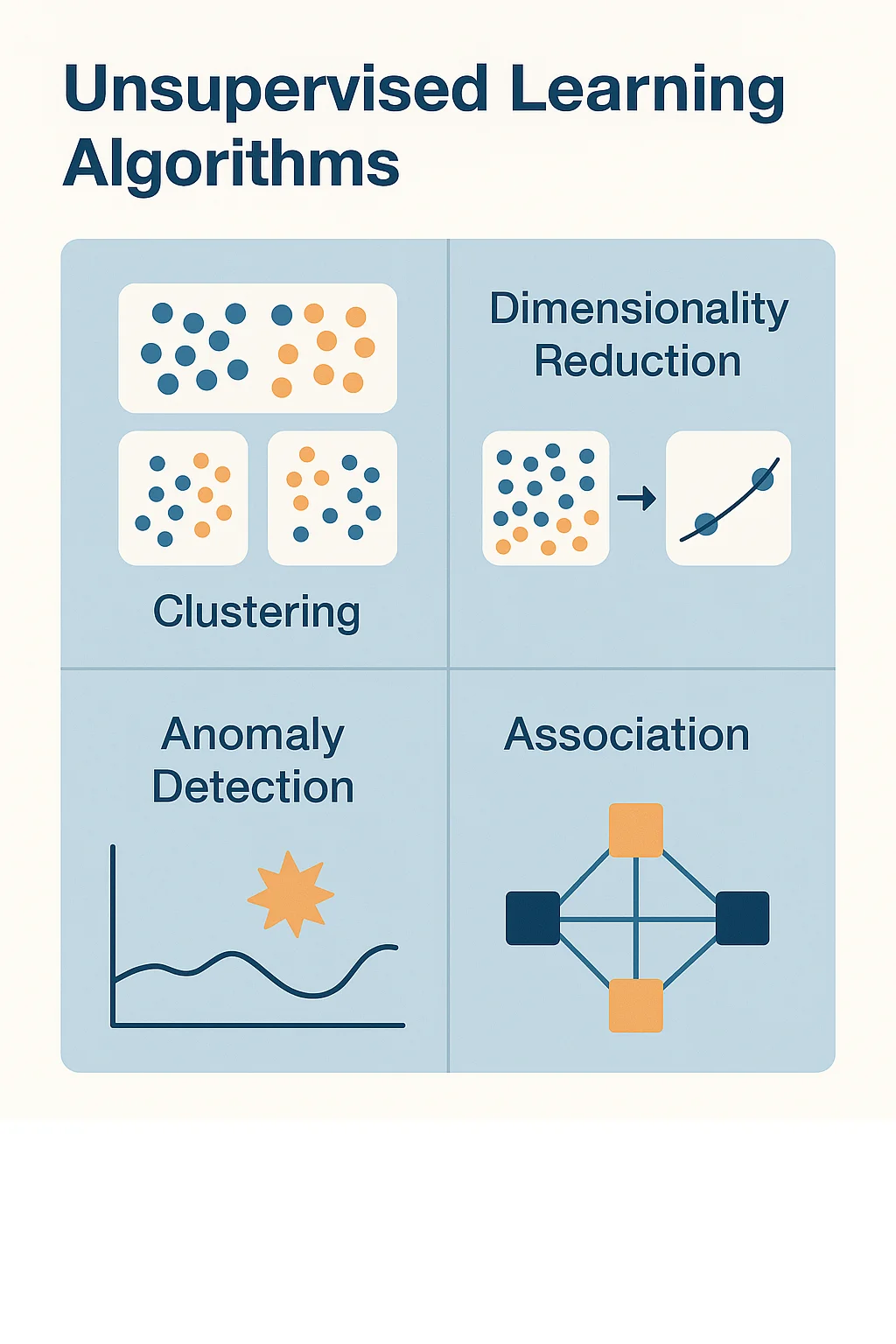
Unlike supervised learning, unsupervised learning works with unlabeled data. The algorithm explores the data to find hidden patterns or groupings — without being told what to look for.
Here are a few popular unsupervised learning techniques:
🔹 K-Means Clustering
K-means is one of the simplest clustering algorithms. You choose how many clusters you want (k), and the algorithm groups the data points into k clusters based on similarity.
Example: A retailer might use k-means to segment customers into groups based on purchase behavior, without knowing in advance how those groups should be defined.
🔹 Principal Component Analysis (PCA)
PCA is used for dimensionality reduction — that is, reducing the number of variables in a dataset while preserving as much information as possible. It transforms the data into a new set of “principal components” that capture the most important patterns.
This is especially useful in fields like image compression or gene expression analysis, where the original data has hundreds or thousands of features.
🔹 Hierarchical Clustering
This algorithm builds a tree-like hierarchy of clusters. It doesn’t require you to predefine the number of clusters. You can cut the tree at any level to form different groupings.
It's often used in bioinformatics, such as classifying species based on genetic similarity.
Reinforcement Learning Algorithms
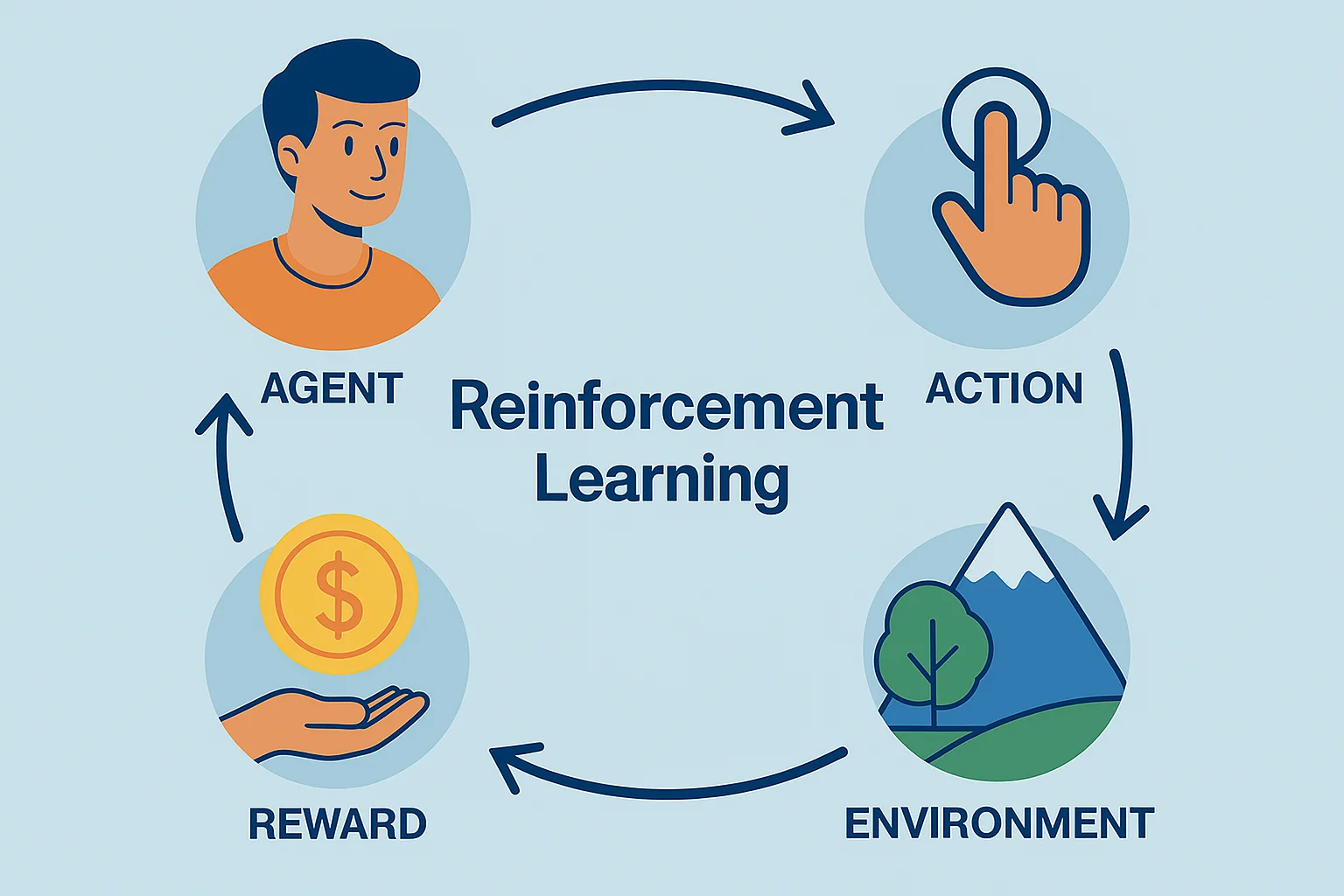
Reinforcement learning (RL) is inspired by how humans and animals learn from experience. In RL, an agent (the AI) learns by interacting with an environment. It receives rewards for good actions and penalties for bad ones, and over time it figures out how to maximize the total reward.
This approach is used in situations where decisions must be made sequentially — like moving through a maze, playing a game, or balancing a robot on one leg.
🔹 Q-Learning
Q-learning is a foundational RL algorithm. It learns the value of taking an action in a given state, which is stored in something called a Q-table. Over time, the algorithm updates this table by exploring the environment and receiving rewards.
Although simple, Q-learning is powerful in discrete, low-complexity environments like board games or basic robotics.
🔹 Deep Q Networks (DQNs)
When the environment is too complex for a simple table (like a video game screen), Q-learning is extended using neural networks — creating a Deep Q Network. These models use the raw environment (like pixels from a screen) as input and learn optimal strategies through trial and error.
This technique famously enabled AI to beat human champions at Atari games like Breakout and Space Invaders.
🔹 Real-World Applications
Reinforcement learning is used in:
- Robotics: teaching machines to walk or grasp objects
- Finance: optimizing trading strategies
- Supply chains: inventory management and dynamic pricing
- Gaming: building intelligent opponents or agents
Unlike supervised learning, RL doesn’t need labeled data. But it usually requires a simulator or environment to interact with, which can make training costly and slow.
Neural Networks and Deep Learning
If machine learning is the brain of AI, then neural networks are the neurons — inspired by the structure of the human brain.
A neural network is a series of connected layers, each made up of nodes (or “neurons”) that perform simple mathematical operations. These layers transform the input data step by step, extracting more abstract features at each level.
🔹 Anatomy of a Neural Network
Input Layer: Takes in raw data (e.g., pixel values, sensor readings)
Hidden Layers: Process data through weights and activation functions
Output Layer: Produces predictions (e.g., category labels, next word)
Each connection has a weight, and each neuron applies an activation function like ReLU or sigmoid. The goal during training is to adjust the weights so that the network minimizes its prediction error.
🔹 Backpropagation
Training a neural network involves forward propagation (making a prediction) and backwards propagation (adjusting weights). The algorithm calculates how far off its prediction was using a loss function, then tweaks all the weights using gradient descent to reduce that error.
This process is repeated over many epochs until the model reaches acceptable accuracy.
🔹 Deep Learning
Deep learning simply refers to neural networks with many hidden layers — often dozens or hundreds. These “deep” models are capable of learning highly complex patterns and are used in:
- Speech recognition (like Siri or Google Assistant)
- Image classification (e.g., cancer detection from scans)
- Language models (e.g., GPT, BERT)
- Self-driving cars (perception and decision-making)
Deep learning is incredibly powerful, but it requires huge amounts of data and computing power, often using GPUs or TPUs to accelerate training.
Conclusion
Machine learning algorithms are the engines that power artificial intelligence — and understanding how they work is key to demystifying AI as a whole. Whether it’s a simple regression model predicting prices, a decision tree diagnosing illness, or a deep neural network generating art, each algorithm has strengths, limitations, and best-use scenarios.
You don’t need to memorize formulas or write code to grasp the big ideas. Knowing the difference between supervised and unsupervised learning, or what makes reinforcement learning unique, can help you:
- Choose the right tool for a task
- Evaluate claims about AI performance
- Spot potential biases or failure modes
- Communicate better with technical teams
As AI becomes more embedded in daily life, algorithmic literacy is as important as basic digital literacy. With this foundation, you’re better equipped to engage with the technology — not just as a consumer, but as a contributor to shaping its future.